Skrevet af:
Søren Riisager
TF*IDF beregner genvejen til topplaceringer på Google
Når Google skal danne sig et indtryk af, hvad din webside handler om, bruges bl.a. den særlige TF*IDF-algoritme. Den er opfundet 16 år før stifteren af Google blev født, og spiller en afgørende rolle for, hvordan dine webtekster bliver indekseret af Google. Derfor bruger vi den også i ContentBeak, når vi skal hjælpe dig med at skabe tekster, der ranker bedst muligt i søgemaskinerne. Læs med, og få styr på, hvad TF*IDF kan gøre for dine placeringer i Google!
Når du bruger ContentBeak til at skrive dine tekster, har du sikkert bemærket de to faner WDF*IDF og TF*IDF i højre side af editoren. De lister hver især en række vigtige ord, som du bør have med i dine tekster, hvis du skal have teksten til at ranke bedst muligt i søgeresultaterne.
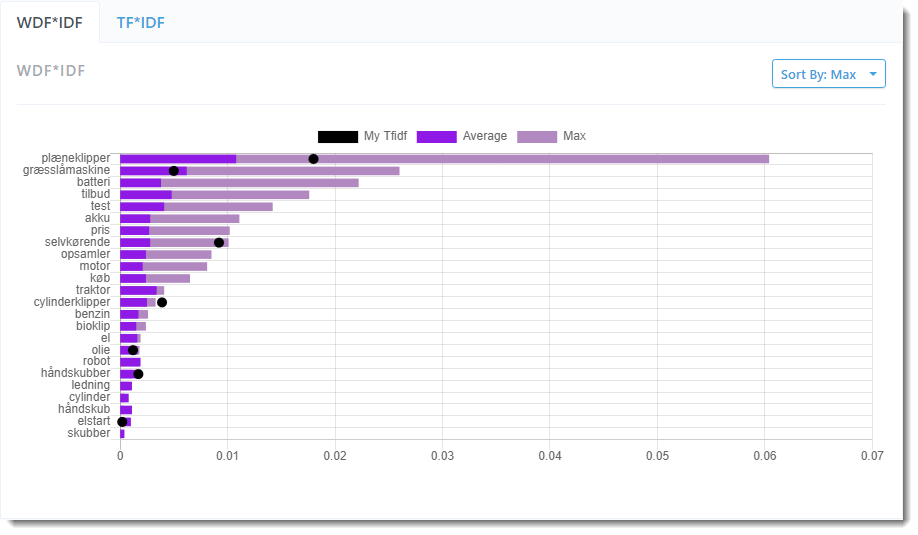
Ud for hvert ord kan du se en søjle, der viser det maksimale og gennemsnitlige antal forekomster, som ordet optræder i top 10-placeringerne for søgeordet. Samt en prik der viser, hvor tit ordet forekommer i den tekst, du har skrevet.
Jo flere af de vigtige ord du får flyttet prikken ud i området lige omkring eller over gennemsnittet, jo bedre chancer har teksten for at komme til at ranke højt i søgeresultaterne for den angivne søgning.
Hvordan er vi kommet frem til de ord?
Ordene er vi som sagt kommet frem til ved at trævle alle søgeresultaterne i top 10 igennem for det pågældende søgeord og score dem ved hjælp af TF*IDF-algoritmen. Den beregner en værdi, der viser, hvor vigtigt hver eneste ord i teksten er i forhold til de andre ord.
Samme algoritme kan også bruges til at vise, hvor vigtig siden er i forhold til de andre sider på hjemmesiden. Eller en hvilken som helst anden dokumentsamling. F.eks. hele internettet.
Ud fra den beregning kan vi skrælle alle de mest almindelige ord fra – dem som kaldes for stopordene. Det gør vi ved at holde TF*IDF-værdien op mod en tilsvarende beregning på tusinder af danske ord. Ligger værdien af algoritmen højt, er der tale om et stopord.
Men ligger værdien i den lave ende, er der tale om et af de ord, der er vigtige at få med, hvis din tekst skal de bedste forudsætninger for at ranke godt for det pågældende søgeord. For når disse ord har betydning i de tekster, der allerede ranker godt, er der en stor chance for, at de får din egen tekst til at ranke lige så godt eller bedre, hvis du også bruger dem i din tekst.
Lad os tage et eksempel
Resultatet af vores analyse vises på WDF*IDF-fanen. TF*IDF-fanen viser kun den rene TF*IDF-værdi uden at tage hensyn til, hvor meget ordet vægter i søgninger på den danske del af internettet.
Vil du f.eks. skrive en tekst, der skal ranke godt for ”græsslåmaskine”, viser WDF*IDF-fanen, at ord som f.eks. ”plæneklipper”, ”tilbud, ”selvkørende”, ”pris”, ”cylinderklipper” og så videre er vigtige at have med. Og ”græsslåmaskine” selvfølgelig.
Men faktisk viser det sig, at hvis du skal have en stor sandsynlighed for at komme til at ranke højt for ”græsslåmaskine”, skal du anvende ordet ”plæneklipper” mere i teksten end dit mest betydende søgeord ”græsslåmaskine”.
Det kan ses af, at ”plæneklipper” står højere på listen på WDF*IDF-fanen end ”græsslåmaskine”, samt at søjlen for både gennemsnitlig og totalt antal anvendelser er længere.
Det virker umiddelbart lidt ulogisk. Men netop fordi ContentBeak kan spotte den slags detaljer, giver den dig en fordel frem for dem, som ikke anvender værktøjet, når de skriver tekster.
Altså giver ContentBeak dig en genvej til at ranke bedre i søgemaskinerne, som ellers er meget svær at spotte.
Hvad er TF*IDF?
Som allerede omtalt kan TF*IDF-algoritmen beregne, hvor vigtigt et bestemt ord er i forhold til alle de andre ord i et dokument – f.eks. en side på din hjemmeside. På samme måde kan algoritmen også regne sig frem til, hvor vigtig siden er i forhold til alle de andre sider på din hjemmeside. Og for den sags skyld, hvor vigtig siden er på hele internettet for det pågældende søgeord!
Algoritmen består af to forskellige komponenter, nemlig ordfrekvensen (på engelsk Term Frequency = TF) og den omvendte dokument frekvens (På engelsk: Inverse Document Frequency = IDF). Og selve algoritmen ganger de to tal sammen.
Hvor svært er det lige at forstå?
Nej, det sidste trin i beregningen er langt den nemmeste del af det. Det er vejen frem til de to parametre, der kræver lidt hjernegymnastik.
Ordfrekvensen TF
Første del er den mest enkle at forstå. Ja, faktisk bruger du den sikkert allerede i dag.
TF angiver hvor mange gange et givent ord optræder i et dokument. Har du f.eks. et dokument på 500 ord, hvor ordet ”græsslåmaskine” optræder 12 gange, vil TF være:
TF(græsslåmaskine) = 12/500 = 0,024
Eller på godt dansk udgør ordet ”græsslåmaskine” 2,4 % af dokumentets 500 ord.
Altså er det nøjagtig samme beregning, som når du skal beregne søgeordstætheden i dit dokument.
Den omvendte dokument frekvens (IDF)
IDF-delen af gangestykket angiver, hvor mange gange det pågældende ord optræder i en given samling dokumenter.
Grunden til at vi tager den omvendte værdi, skyldes at, et bestemt ord kan kvantificeres af den omvendte funktion af antallet af dokumenter, som ordet optræder i. Ved at bruge logaritmefunktionen får vi samtidig gjort tallet kortere, og dermed lettere at overskue.
Derved får vi de ord, som må anses for at have en vis signifikans for, hvad dokumentet handler om, til at træde frem i forhold til de mest anvendte ord. Det er dem, vi normalt bruger til at binde dokumenterne sammen med. Altså spotter algoritmen på den måde betydende ord for dokumentets emne som f.eks. ”plæneklipper” og sorterer alle de almindelige ord (stopordene) som f.eks. ”og”, ”for”, ”at” og så videre fra.
Samme beregning for samtlige sider på din hjemmeside vil give dig en ide om vigtigheden af den enkelte sides emne på din hjemmeside. På samme måde kan vi også tage udgangspunkt i alle dokumenter på den danske del af internettet. Dem har vi analyseret for at skabe en tabel over TF*IDF-værdier for tusindvis af danske ord. Derved har vi noget at holde de fundne TF*IDF-værdier op imod.
Når Google benytter algoritmen, tager de alle sider på internettet i betragtning. Og siger vi, at internettet består af 10 billioner sider, og der er 300.000 sider, der står ”plæneklipper” i, bliver den omvendte dokument frekvens:
IDF(græsslåmaskine) = log(10.000/300)=1,52
For overskuelighedens skyld har vi ”ensbenævnt” tallene på antal betydende nuller. Det gør det lidt nemmere at holde beregningen på en enkelt linje – selv på en mobiltelefon.
Tager vi den TF, som vi beregnede før, og ganger samen med IDF-værdien for ”græsslåmaskine” får vi:
TF*IDF(græsslåmaskine)= 0,12 * 1,52 = 0,182
Det resultat holder vi så op imod resultaterne for alle de danske ord, vi har scoret med algoritmen. Det fortæller os, at ordet har en høj betydning for, hvad siden handler om.
Samtidig spotter vores gennemgang af top 10-søgeresultaterne for ”græsslåmaskine”, at der også er et andet ord, der skiller sig ud. Nemlig ”plæneklipper”. Meget logisk egentlig, eftersom det jo i dag anvendes som synonym for ”græsslåmaskine”, endskønt den ret teknisk bruger en anden metode til at afkorte græsset.
Signifikansen af ”plæneklipper” er så høj, at det SKAL tages med i teksten. Faktisk så meget, at ”plæneklipper” gerne skal optræde oftere end ”græsslåmaskine”, for at siden skal have en rimelig chance for at komme til at ranke for ”græsslåmaskine”.
Du behøver ikke forstå TF*IDF-algoritmen, for at kunne bruge ContentBeak
Det gør ikke noget. For heldigvis behøver du ikke forstå TF*IDF-algoritmen for at kunne bruge ContentBeak. Vi har bare brugt algoritmen til at lave alt regnearbejdet, så vi har fundet de vigtigste ord frem for dig.
De vises i grafen på WDF*IDF-fanen. Så kan du nemt se, hvilke ord der har betydning for din teksts placeringer, og hvor tit du har fået dem brugt i din tekst i forhold til det gennemsnitlige og den maksimale brug af ordet, i de tekster der allerede ranker i top 10.
Jo flere af ordene, du får til at optræde i teksten, så de er brugt lige omkring den gennemsnitlige antal gange eller lige over. Jo bedre chancer har din tekst for at komme til tops i Google.
Se! Det gør det nemt at skrive tekster, der får gode placeringer i søgeresultaterne.
Brug Contentbeak til at slå dine konkurrenter

Forslag til gæsteindlæg sendes til [email protected]
Ingen risiko
Hvis du publicerer indhold skrevet med hjælp fra Contentbeak, og det ikke øger dine salg, leads eller
placeringer på Google, får du de sidste 3 måneders abonnement tilbage.

Skal du have flest mulige mennesker til at forstå det, du skriver? Så skal du sørge for at skrive det, så alle kan forstå det. Og vil du have et mål for, hvor let din tekst er at forstå? Så er lix-tallet en god rettesnor for præcis det.

Skal du have flest mulige mennesker til at forstå det, du skriver? Så skal du sørge for at skrive det, så alle kan forstå det. Og vil du have et mål for, hvor let din tekst er at forstå? Så er lix-tallet en god rettesnor for præcis det.

Der er selvfølgelig allerede måder, hvorpå du kan få en idé om, hvordan dine bruger konsumere dit indhold. Du kan eksempelvis allerede nu finde gennemsnitlig tid på siden i Google Analytics. Det tal kan du finde under Adfærd > Sideindhold > Alle sider. Her kan du se, hvilke sider der er er besøgt - og selvfølgelig den førnævnte gennemsnitlige tid på hver side, men der er nogle forskellige årsager til, at denne metrik ikke er 100% retvisende. Én grund er, at jeg godt kan tilgå dit blogindlæg, men måske blive distraheret af noget andet og derfor minimerer dit indhold. I så fald vil Analytics tælle min tid på siden i op til 30 minutter og herefter vil den registerede session udløbe. Det kan også være, at jeg har fundet dit blogindlæg, men igen i blev distraheret kort, og derfor aldrig kom i gang med at læse det. Jeg lukker derfor vinduet igen efter 1 minut. Har jeg læst dit indhold? Det vil du måske umiddelbart udlede i dine Analytics-data, men virkeligheden var desværre en anden. Sidst, men ikke mindst, kan jeg have fundet dit blogindlæg, hurtigt scrollet det igennem, men ikke rigtige have læst det. Surt show. Der er altså masser af muligheder for Analytics til at give dig misvisende data. Med nedenstående guide prøver vi at komme tættere på virkeligheden.

De kommende dage vil årets første store Google opdatering rulle ud på alle sprog. Den er direkte målrettet godt indhold eller mangel på samme. Google har opfordret alle tekstforfattere til at stille sig selv følgende spørgsmål - når de skal lave eller opdatere indhold på nettet. Spørgsmål om indhold og kvalitet Leverer indholdet originale oplysninger, rapportering, forskning eller analyse? Indeholder indholdet en væsentlig, komplet eller omfattende beskrivelse af emnet? Indeholder indholdet indsigtsfuld analyse eller oplysninger udover det sædvanlige? Er indholdet blot en kopi fra andre kilder eller er det omskrevet så det giver en betydelig merværdi? Indeholder overskrift og / eller sidetitel en beskrivende, hjælpsom oversigt over indholdet? Undgår overskrift og / eller sidetitel at overdrive eller chokere? Er det den slags side, du gerne vil bogmærke, dele med en ven eller anbefale? Vil du forvente at se dette indhold i et trykt magasin eller bog? Spørgsmål om ekspertise Præsenterer indholdet oplysninger på en måde, der får dig til at stole på det, såsom klar kildehenvisning, bevis for den involverede ekspert, baggrund om forfatteren eller den side, der udgiver indholdet, f.eks. Gennem links til en forfatterside eller en "Om os" side? Hvis du undersøgte hjemmesiden der producerede indholdet, ville du da få et indtryk af, at det er en autoritet du kan stole på eller som er bredt anerkendt indenfor emnet? Er dette indhold skrevet af en ekspert eller entusiast, der beviseligt kender emnet godt? Er indholdet fri for let faktuelle fejl? Vil du have det godt med at stole på dette indhold til problemer, der vedrører dine penge eller dit liv? Præsentations- og produktionsspørgsmål Er indholdet fri for stavefejl eller stilistiske problemer? Er indholdet produceret godt, eller forekommer det sjusket eller hurtigt produceret? Er indholdet masseproduceret af eller outsourcet til et stort antal forfattere eller spredt over et stort netværk af sider, så de ikke får så meget opmærksomhed eller pleje? Har indholdet en overdreven mængde annoncer, der distraherer eller forstyrrer hovedindholdet? Vises indholdet godt på mobile enheder? Sammenlignende spørgsmål Indeholder indholdet en betydelig værdi sammenlignet med andre sider i søgeresultaterne? Ser det ud til, at indholdet tjener de ægte interesser hos besøgende på hjemmesiden eller ser det ud til at eksistere udelukkende for at ranke godt i søgemaskinerne? Du har brug for hjælp når du skal lave godt indhold Hvis du ikke har 100% styr på hvilke søgeord dine potentielle besøgende bruger, eller hvad deres intention er, taber du. Da jeg startede udviklingen af Contentbeak for over et år siden, var det fordi jeg selv manglede et værktøj som kunne sikre godt indhold. Med data fra Google Ads og Google Suggest samt en hjemmebygget scraper som henter alt indhold fra top 15 af Google, kan jeg i dag analysere mig frem til hvilke søgeord og intentioner de potentielle brugere har indenfor et givent søgeord. Denne opdatering fra Google er ikke kun godt for Contentbeaks eksistens, men også for dig som bruger. Lad os skabe bedre indhold sammen.

Underrubrikken – også kaldet manchetten – øger dine chancer for at holde de besøgende længere på siden, fordi den nemt fanger deres opmærksomhed lige under overskriften. Det gør den perfekt til at uddybe overskriften og sælge indholdet på siden ind. Læs med her og lær, hvordan du bruger underrubrikken til at skabe bedre placeringer i søgeresultaterne. Det er efterhånden mange år siden, on-page SEO-arbejde kun handlede om at placere dine søgeord de rigtige steder i de rigtige heading-tags og det rigtige antal gange i indholdet på de enkelte sider. I dag bruges heading-tags primært til at forstå, hvordan dit indhold er struktureret , samt hvad teksten og de enkelte afsnit i den handler om. I stedet handler SEO-arbejdet for dig som tekstforfatter meget om bl.a. at holde de besøgende længst muligt på siden. Det bekræfter nemlig Googles vigtige Rank Brain-”algoritme” i, at din side var den rigtige at vise for den pågældende søgning. Det kan du gøre dels ved at servere noget godt, gennemarbejdet kvalitetsindhold, og dels ved at bruge forskellige visuelle elementer, som fanger de besøgendes opmærksomhed. F.eks. i form af punktopstillinger og et alt et for overset element på mange hjemmesider. Nemlig underrubrikken.

Jakob hamrer løs på skrivemaskinen og er snart klar til at give dig guld ...

Er du ikke er gået i gang med SEO, fordi du tror, at SEO-tekster er dårlige tekster? Så læs med her, for med den antagelse går du glip af mange besøgende, kunder og kroner, og antagelsen er direkte forkert. Det har altid været Googles fornemmeste opgave at give mennesker de bedste svar på deres søgninger. Og før Googles søgerobotter blev så dygtige, som de er nu, var konklusionen: ”En tekst, hvor ordet ”pære” indgår mange gange, er en god tekst om pærer. Derfor placerer vi den pågældende tekst højt, når nogle googler ”pære”.” Med andre ord blev vi SEO-skribenter honoreret for søgeordsspam. Så, ja, engang var SEO-tekster virkelig dårlige tekster. Robotterne er heldigvis blevet meget mere intelligente siden dengang. Nu vurderer de en tekst ud fra flere hundrede forskellige faktorer, der alle handler om, hvorvidt læseren får en god oplevelse af at læse teksten. Derfor laver vi, SEO-skribenter, selvfølgelig ikke søgeordsspam mere. Og det har vi ikke gjort længe.

SEO-tekster. Hold op, det begreb er efterhånden blevet brugt meget og i forskellige sammenhænge. Det er egentlig en ret farlig cocktail, da det typisk refererer til de ”gamle dage”, hvor alt handlede om at mase det primære søgeord ind i en tekst så meget som overhovedet muligt. Ligesom dinosaurerne er ”SEO-tekster” kun noget, der bliver brugt i fortællinger inden sengetid. Alternativt fremgår det måske i nogle gamle tidsskrifter. Betydningen ”SEO-tekster” har nemlig gennemgået en radikal ændring, og nu handler det i langt højere grad om kvalitet, forståelsen af søgehensigten, men selvfølgelig også brugen af de rette søgeord. Alt det – og meget mere – kigger jeg nærmere på i teksten nedenfor, så du får fyldt dit arsenal op med de nyeste våben, så du kan skrive den moderne ”SEO-tekst”.
